
Anthropic’s Claude AI Overthrows ChatGPT on Chatbot Arena Leaderboard

While ChatGPT from Open AI enjoys the largest mainstream mindshare of all generative AI tools, its top spot has been stolen by the top-of-the-line Claude 3 Opus from perennial contender Anthropic on a popular crowdsourced leaderboard used by AI researchers.
Claude’s ascension in the Chatbot Arena rankings marks the first time that OpenAI’s GPT-4, which powers ChatGPT Plus, has been dethroned since it first appeared on the leaderboard in May of last year.
Chatbot Arena is run by Large Model Systems Organization (LMSYS ORG), a research organization dedicated to open models that support collaboration between students and faculty at the University of California, Berkeley, UC San Diego, and Carnegie Mellon University. The platform presents users with two unlabeled language models and asks them to rate which one performs better based on any criteria they deem fit.
After aggregating thousands of subjective comparisons, Chatbot Arena calculates the “best” models for the leaderboard, updating it over time.
[Community creation]Top-15 Chatbot Arena LLM ratings (May ’23 – Now)
Credit: Peter Gostev https://t.co/OgnLu3rj64 pic.twitter.com/Ueq7DZpu8N
— lmsys.org (@lmsysorg) March 27, 2024
That subjective approach, based on participants’ disparate personal tastes, is what sets Chatbot Arena apart from other AI benchmarks. Model trainers cannot “cheat” by tailoring their models to beat the algorithm, as they might with quantitative benchmarks. By measuring what people simply prefer, Chatbot Arena is a valuable, qualitative resource for AI researchers.
The platform collects users’ feedback and runs it through the Bradley-Terry statistical model to predict the likelihood of a particular model outperforming others in direct competition. This approach enables the generation of comprehensive statistics, including confidence interval ranges for Elo rating estimates—the same technique used to measure the skill of chess players.

The top 10 LLMs ranked by the Chatbot Arena. Image: Huggingface
Claude 3 Opus’s rise to the top is not the only significant development on the leaderboard. Claude 3 Sonnet (the medium size model available for free) and Claude 3 Haiku (a smaller, faster model), also developed by Anthropic, are currently in 4th and 6th place, respectively.
The leaderboard includes different versions of GPT-4, such as GPT-4-0314 (the “original” version of GPT-4 from March 2023), GPT-4-0613, GPT-4-1106-preview, and GPT-4-0125-preview (the latest GPT-4 Turbo model available via API from January 2024). According to the ranking, Sonnet and Haiku are both better than the original GPT-4 with Sonnet also outpacing a tweaked version launched by OpenAI on June 2023.
This also means that, sadly, there is only one open-source LLM currently in the top 10: Qwen, with Starling 7b and Mixtral 8x7B the only other open models in the top 20.
One of the advantages of Claude over GPT-4 is its token context capacity and retrieval capability. The public version of Claude 3 Opus handles over 200K—and the organization claims to have a restricted version capable of handling 1 million tokens with almost perfect retrieval rates. This means that Claude can understand longer prompts and retain information more effectively than compared to GPT-4 Turbo, which handles 128K tokens and loses its retrieval capabilities with long prompts.

Recall accuracy of Claude 3 Opus vs GPT-4 Turbo. Image from Decrypt using data from Anthropic and Greg Kamradt.
Google’s Gemini Advanced has also been gaining traction in the AI assistant space. The company offers a plan that includes 2TB of storage and AI capabilities in the suite of Google products for the same price as a Chat GPT Plus subscription ($20 per month).
The free Gemini Pro is currently ranked number 4, between GPT-4 Turbo and Claude 3 Sonnet. The top-of-the-line Gemini Ultra model is unavailable for testing and is not yet featured in the rankings.
Edited by Ryan Ozawa.



 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  Dogecoin
Dogecoin  USDC
USDC  Cardano
Cardano  Stellar
Stellar  Hedera
Hedera  Bitcoin Cash
Bitcoin Cash  LEO Token
LEO Token  Litecoin
Litecoin  Algorand
Algorand  OKB
OKB  Cosmos Hub
Cosmos Hub  Gate
Gate  Maker
Maker  KuCoin
KuCoin  IOTA
IOTA  NEO
NEO  Zcash
Zcash  Polygon
Polygon  Synthetix Network
Synthetix Network  Tether Gold
Tether Gold  TrueUSD
TrueUSD  Holo
Holo  0x Protocol
0x Protocol  Enjin Coin
Enjin Coin 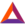 Basic Attention
Basic Attention  Siacoin
Siacoin  Ravencoin
Ravencoin